

 7 december 2020 Information om det svenska byggnadsbeståndet har ökat de senaste åren bland annat genom att data finns tillgänglig i energideklarationerna som visar vilken energiprestanda olika byggnader har. Baserat på denna information kan potentialen för energieffektiviserande åtgärder beräknas byggnadsspecifikt. Resultaten kan sedan användas för att utforma nationella strategier för energieffektivisering. Problemet är att det saknas viss information som kan vara avgörande för att veta vilka åtgärder som är lämpliga för en viss byggnad. Med hjälp av maskininlärningsmetoder har vi lyckats identifiera ett antal sådana parametrar (eller karaktärsdrag) hos byggnader inom flerbostadshusbeståndet byggt 1945–1975. Läs hela artikeln som pdf här.
7 december 2020 Information om det svenska byggnadsbeståndet har ökat de senaste åren bland annat genom att data finns tillgänglig i energideklarationerna som visar vilken energiprestanda olika byggnader har. Baserat på denna information kan potentialen för energieffektiviserande åtgärder beräknas byggnadsspecifikt. Resultaten kan sedan användas för att utforma nationella strategier för energieffektivisering. Problemet är att det saknas viss information som kan vara avgörande för att veta vilka åtgärder som är lämpliga för en viss byggnad. Med hjälp av maskininlärningsmetoder har vi lyckats identifiera ett antal sådana parametrar (eller karaktärsdrag) hos byggnader inom flerbostadshusbeståndet byggt 1945–1975. Läs hela artikeln som pdf här.
I Sverige byggdes en betydande andel av våra befintliga flerbostadshus under två expansiva perioder, Folkhemmet och Miljonprogrammet (1965 1974). Byggnaderna byggdes i industriell skala med standardiserade processer. Dessa byggnader har relativt låg energiprestanda och har komponenter som nått sin tekniska livslängd. Det finns därmed potential att göra åtgärder för att minska energibehovet i samband med att man renoverar. Många olika initiativ har drivits för att ta fram åtgärdspaket för energieffektivisering omfattande exempelvis tilläggsisolering, fönsterbyten och installation av ventilation med värmeåtervinning, bland annat inom BeBo (Beställargruppen bostäder). Baserat på dessa åtgärdspaket kan energieffektiviseringspotentialen och kostnaden för att göra åtgärderna för denna del av byggnadsbeståndet uppskattas. Problemet med sådana analyser är att åtgärdspaketen inte är lämpliga för alla byggnader. Byggnader med en kulturhistoriskt värdefull fasad är exempelvis inte lämpliga att tilläggsisolera. Byggnadsspecifik information finns tillgänglig från flera datakällor på nationell nivå såsom energideklarationerna och fastighetsregistret. I projektet Nationell Byggnadsspecifik Information har RISE fört samman dessa typ av register i en större databas. Vissa byggnadsspecifika parametrar som är nödvändiga för att bestämma vilka energieffektiviseringsåtgärder som är lämpliga för en specifik byggnad finns dock inte i dessa databaser.
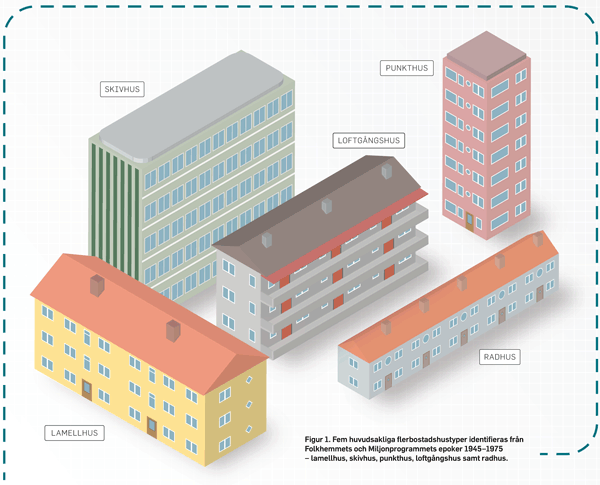
Fem huvudsakliga flerbostadshustyper identifieras från Folkhemmets och Miljonprogrammets epoker: lamellhus, skivhus, punkthus, radhus och loftgångshus. Bilder av några av dessa byggnadstyper kan ses i figur 1. Eftersom energieffektiviseringspotentialen är kopplad till byggnadstyp så kan denna parameter vara mycket användbar för analys av lämpliga energieffektiviseringsåtgärder i byggnadsbeståndet.
Målet med studien var att undersöka om maskininlärning kan användas för att förutsäga byggnadsspecifika parametrar som kan komplettera befintlig information om byggnaderna i databasen. Studien har avgränsats till flerbostadshus som byggdes mellan åren 1945 och 1975 och omfattar bara tre byggnadsspecifika parametrar (i) byggnadstyp, (ii) fasadmaterial, och (iii) takfot som kan ha betydelse för valet av renoveringsåtgärder och därmed energibesparingspotentialen i beståndet.
Val av metod
Maskininlärning kan vara en lämplig metod för att förutsäga parametrar effektivt i en så stor skala som ett byggnadsbestånd. Maskininlärning upptäcker mönster i data som kan användas för att förutsäga olika parametrar i större datamängder. Fördelen med maskininlärning är att användaren inte behöver programmera modellerna uttryckligen eftersom den automatiskt analyserar mönster i stora mängder data. Detta sparar tid och ansträngning under modelleringsfasen jämfört med andra modelleringstekniker. För att kunna använda maskininlärning behövs någon form av träningsdata.
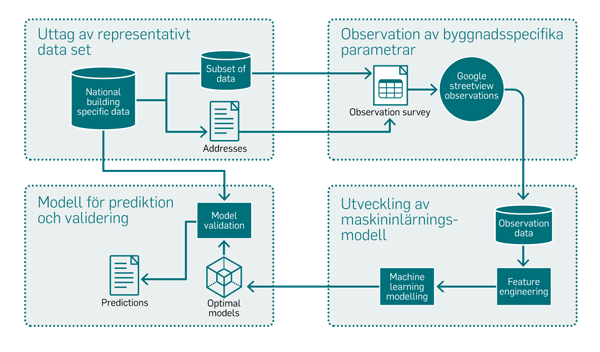
Figur 2. Illustrationen visar de fyra stegen i metoden: • Uttag av representativt data set • Observation av byggnadsspecifika parametrar • Utveckling av maskininlärningsmodell • Modell för prediktion och validering.
En grafisk illustration över den använda metoden kan ses i figur 2. Metoden består av fyra steg, (i) skapa ett representativt dataset, (ii) observera byggnadsspecifika parametrar, (iii) maskininlärningsmodellering och (iv) modell för förutsägelse och validering. Var och ett av dessa steg beskrivs nedan.
Första steget innebar att göra ett slumpmässigt urval av drygt 500 flerbostadshus som byggdes mellan åren 1945 och 1975 från den nationella byggnadsspecifika databasen. Sannolikheten för att byggnaden skulle väljas var proportionell mot byggnadens uppvärmda area. Med andra ord, ju mer uppvärmd yta, desto större är sannolikheten att inkluderas i uttaget. Det resulterade i en uppsättning av drygt 500 adresser till byggnader för vilka observationer gjordes i nästa steg.

Figur 3. Exempel på gatuvy från Google Maps som användes vid observation av byggnadsspecifika parametrar.
Identifikation av byggnadsspecifika parametrat
Observationer av byggnadsspecifika parametrar gjordes genom att titta på byggnaden i en gatuvy från Google Maps, figur 3. De parametrar som noterades var: typ av byggnad, typ av fasadmaterial, utformning av tak och takfot. Det är viktigt att det är personer med kunskap om byggnader som gör observationerna. För att säkerställa att bedömningar som gjordes av olika personer överensstämmer gjordes en jämförelse av bedömning av 13 byggnader. Om byggnaden inte kunde observeras från Google Maps gatuvy av någon anledning så registrerades detta också.
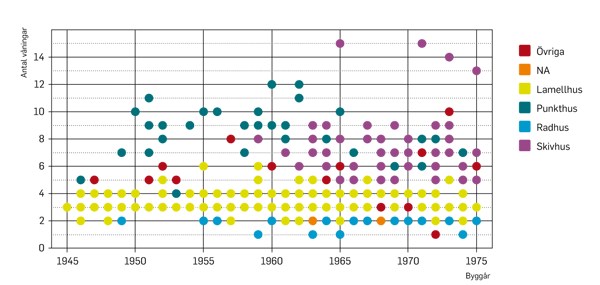
Figur 4. Sambandet mellan byggnadsår och antal våningar för olika byggnadstyper.
Information från observationerna samt från fastighetsregistret och energideklarationer för de drygt 500 byggnaderna sammanställdes för att användas som träningsdata och valideringsdata. Informationen omfattar bland annat byggår, uppvärmd bostadsyta, antal våningar, antal lägenheter, antal trapphus, årlig energianvändning samt byggnadstyp, fasadmaterial, utformning av tak och takfot. Utifrån observationerna fördelade sig de drygt 500 byggnaderna på byggnadstyperna lamellhus, punkthus, radhus och skivhus samt övriga och icke identifierbara (N/A). I figur 4 exemplifieras hur byggnadstyp korrelerar med andra byggnadsspecifika parametrar.
Modellering av maskininlärning
Baserat på det insamlade materialet var det möjligt att utveckla maskininlärningsmodeller. Detta gjordes i två steg: val av indata (exempelvis baserat på expertkunskap) och val av modell som ska användas. Modellerna kan antingen vara allt från enkla linjära till komplexa ickelinjära modeller. Utmaningen är att hitta modellen med minst avvikelser när man applicerar den på oberoende testdata. Av de drygt 500 observationerna användes 80% av data för att träna modellen och 20% av data användes för att testa och utvärdera modellen. De bästa modellerna som togs fram i föregående steg användes därefter på hela databasen för att förutsäga byggnadsspecifika parametrar i hela flerbostadshusbeståndet byggt mellan 1945-1975. Förutsägelserna validerades mot ett slumpmässigt urval av byggnader för att kunna uppskatta hur noggranna förutsägelser som kan göras med modellerna.
Läs hela artikeln som pdf här.
 Claes Sandels
Claes SandelsTekn. doktor, forskare RISE
 Mikael Mangold
Mikael MangoldTekn. doktor, forskare RISE
 Jenny von Platten
Jenny von PlattenTekn. lic., doktorand avd. för
Byggnadsfysik LTH/RISE
 Kristina Mjörnell
Kristina MjörnellDocent, avd för Byggnadsfysik,
LTH/RISE